forSharingAccidentally: How Permissive Defaults and Unclear Documentation Cause Mistakes
By Jacob Weisz - 12 May 2025
tl;dr: We found a vulnerability in a few apps allowing unauthorized access to grains via API tokens. The last section has recommended actions.
We think of Sandstorm first and foremost as a security product. This means, in practice, we think of the security implications first, and the usability concerns second.
From time to time, when poking around our own project, we question the assumptions we make day-to-day. In this case, we decided to test a claim in the documentation, and it revealed an information-disclosure issue in multiple apps.
The problem
The issue in question is regarding Sandstorm’s use of “offer templates”, which are a way for apps to distribute API keys to users, often to connect client apps. Offer templates are a text template defined by the app which specifies how an API key will be shown to a user. The template, with the API key inserted, is then displayed by Sandstorm in an iframe. This approach is intended to prevent Sandstorm apps from reading their own API keys.
Offer templates are created by apps with some parameters. Sandstorm requires rpcId which identifies the template in case your app has multiple, and template which contains the actual template text. Several optional parameters are also available to describe the API key, style the template, and most critically set its authorization. roleAssignment restricts the key’s permissions by tying it to an app-defined “role”. forSharing determines whether the key meant to be given to someone other than the user, but what does this imply exactly?
In the documentation, it clearly states that if you use the forSharing option, the token in the offer template is detached from the user and can be reconfigured into a grain sharing link, in the format of https://SERVER/shared/TOKEN. This presents the natural assumption (and fatal mistake) that if you do not use forSharing, you cannot use the token in the form of a grain sharing link.
However, that assumption is incorrect. Regardless of the existence of the forSharing option, every API token works as a share token. Therefore, in the minimum offer template configuration, where neither roleAssignment nor forSharing is set, an API token can be used to access the full UI of the Sandstorm grain, at the same permissions as the user who created the token.
Another assumption which one might casually make, if API keys are just API keys, is that you can restrict the bounds of an API key using the app’s apiPath. This setting limits the root URL that an API call can make when used as an API key. But because the API tokens can be used to access the grain UI, that assumption is also perilous. API tokens are, fundamentally, granted capabilities, where knowing the resource also conveys the ability to use the resource.
Affected apps
In the case of most Sandstorm apps, this is actually not a significant issue: Users expect their client apps to have full access to their grains. For instance, a few apps use offer templates for Git clients and grant full access. This is okay because for these apps, each grain contains a single repository and full write access is expected. However, there’s a small category of Sandstorm apps where the token from the offer template is published publicly: Analytics tools.
We identified two analytics tools for Sandstorm which do not appropriately restrict access to the tracking token: Hummingbird and Sandstorm Error Collector. Notably, the Sandstorm Error Collector is used in the Sandstorm install script to allow people who fail to install Sandstorm to send the error code to us. It is possible to take the token from the installer script and use it to open the grain and see error reports. However, no user-identifying data is collected by this app.
Hummingbird is a website analytics tool. Anybody visiting a website that uses Hummingbird can view its source and obtain the API token. Hummingbird does define a “trackee” role, but for whatever reason the offer template did not end up using it for roleAssignment. As a result, it would be possible to use the API token to open the grain and watch analytics from currently active visitors to the site (not historical data). This includes location data which is obtained by the visitors’ IP addresses. While IP addresses are not directly exposed, the exposed location data could in theory be used to identify a “record” in the app’s GeoIP database which is associated with a set of possible IP addresses. The number of IP addresses in a record varies. More than 99% of IP addresses are in a record with 100 or more IP addresses. About 15,000 IP addresses are in a record with 10 or less. 911 IP addresses are in their own record, and could thus be identified uniquely by the visitor’s location. This is unfortunately non-zero exposure, but ultimately quite limited. (Daniel Krol did most of the investigation on the impact for this application.)
Additionally, the RMM app I am developing, XRF Sync, also should have used tokens with less permissive roles. However, in general different customers or tenants should be confined to their own grains, so the impact here is similarly limited.
Remediation and recommendations
We’ve patched Sandstorm Error Collector and XRF Sync. We’ve also developed a fix for Hummingbird, but the author has not yet been reached to assist with publishing.
Suggested actions for users: If you use Sandstorm Error Collector or XRF Sync and are concerned about access to the grain, you should update your app(s), revoke your API tokens in the “webkey” menu, and create new tokens for your use. If you use Hummingbird, we can only recommend that you revoke all API tokens and stop using the app for now.
We will update Sandstorm’s documentation to highlight that an API token can always be used to access the grain UI in the form of a sharing URL.
Critically for the future, we do not think security-critical properties should be optional. We’re going to move to start including roleAssignment in all offer templates, even when all permissions are expected, with a goal of making it a required configuration in Tempest. In the interim, app review will no longer accept submissions of packages which use offer templates without defining roleAssignment explicitly.
Getting On Zulip
By Daniel Krol - 29 Jan 2025
We are officially moving the chat portion of the Sandstorm Community to Zulip. Important announcements will go on our mailing lists, and you are still encouraged to continue to use them for questions if you prefer email over chat.
Zulip is an organized team chat app designed for efficient communication. It is built by a FOSS company which offers free hosting to FOSS projects such as ours. We appreciate this, and invite you to give them a look.
If you are still on Matrix, or especially if you are on IRC, we invite you to move over. Zulip will be a great way to collaborate at a faster pace than our mailing lists. You don’t need to install an app to join, though apps are available. You don’t even need to log in to see what’s happening.
A Little History
The Sandstorm project started out on IRC. This was long before the community fork. It was originally on Freenode, and eventually moved over to Libera.Chat as many others did.
We eventually bridged our Libera.Chat room to Matrix, allowing IRC and Matrix users to interoperate. Then in 2023, Libera.Chat decided to shut down their Matrix IRC bridge. First temporarily, then permanently. You can see comments on this topic from Matrix and Libera.Chat.
So now we had a split chat room, IRC and Matrix. By this time, most people had switched over to the Matrix side, which we decided to make the official one. It was still labeled as a sort of Libera.Chat “bridge to nowhere”, but we didn’t want to lose more people just to change our channel name. We did our best to let the few remaining IRC users know that the community moved over, though a handful people missed the message and stuck around.
But then, some time later, we were made aware of another problem: our channel was not allowing new members to join. We reached out to Matrix when we realized this, and we have yet to hear back. Perhaps moving to a new (non-bridge) Matrix room would fix it. But frankly, just as a personal preference, we were never in love with Matrix in the first place. If we were going to move, we were open to exploring new options.
More recently, one of our community members had been exposed to Zulip in a couple other open source communities. He suggested it for Sandstorm, so we tried it out. It’s a different animal than Matrix, but we ultimately decided that it would be a good fit for our community. We decided to make the switch!
Why Zulip?
Zulip conversations are organized into Channels and Topics. A Topic corresponds roughly to a “thread” in other chat apps, except that it is mandatory. That is, every post in a Channel has to be on a certain Topic. You can view a Channel as a whole or focus on a given Topic. This takes a little getting used to, but it keeps things organized.
If discussion in a thread starts to drift into a different subject, an admin can move those posts to a new appropriate Topic. Similarly Topics can be moved to a more appropriate Channel. This keeps us focused.
Channels can be made public and searchable on the web, and we have made most of our channels public. Specific conversations are linkable (such as the link in the paragraph below). As with mailing lists, this is very useful for an open source project. For instance, a Github pull request can link to where the idea was previously hashed out on Zulip.
Not to mention, Zulip is just snappy. It’s not bulky like Slack or Matrix. We find all these features conducive to having productive conversations. This is where we can “get in the weeds” and work things out.
They’re also great to work with. They responded and resolved a bug report overnight. (Again, by contrast we reached out to Matrix for help with the bridge and we never heard back).
Desert Atlas: A Self-Hosted OpenStreetMap App for Sandstorm
By Daniel Krol - 05 Dec 2023
Hi, my name is Dan. This is my first time posting on the Sandstorm blog. I got involved with Sandstorm almost a decade ago. I imagined a day when open data would be easily deployed via Sandstorm onto a mesh network (a lofty goal, I know), so I created a package for an existing application called Kiwix for easy hosting of sites like Wikipedia.
I still have this vision in mind. Today, I’m announcing the result of a more ambitious effort.
Introducing Desert Atlas
Sandstorm, meet OpenStreetMap. OpenStreetMap, meet Sandstorm.
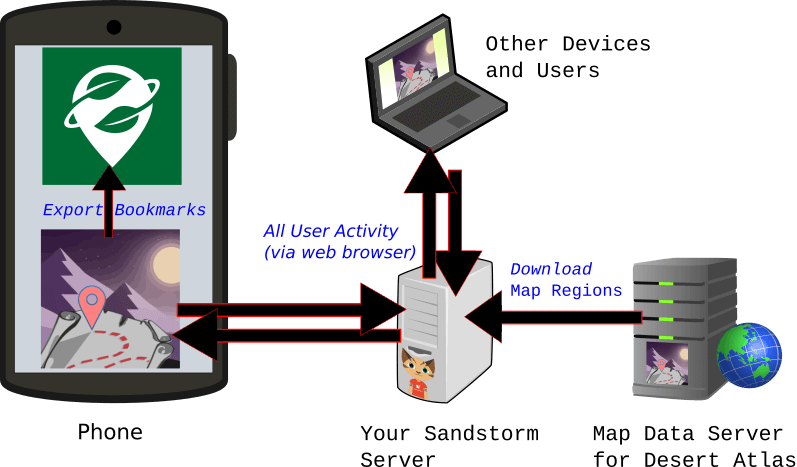
Desert Atlas is the world map for Sandstorm. With Desert Atlas, you can privately collaborate with friends to search for destinations and save them as bookmarks for use on the go.

You may be familiar with OSM phone applications like Organic Maps that download entire regions of the map at once so you can search and browse privately. Desert Atlas was inspired by this model. Unlike many OSM web applications, the map regions are fully hosted in your Sandstorm grain, and downloaded with the same ease of point-and-click that you expect from Sandstorm. Unlike Organic Maps, Desert Atlas makes it easy to share your map with a friend or plan a trip together on a private server that you trust.
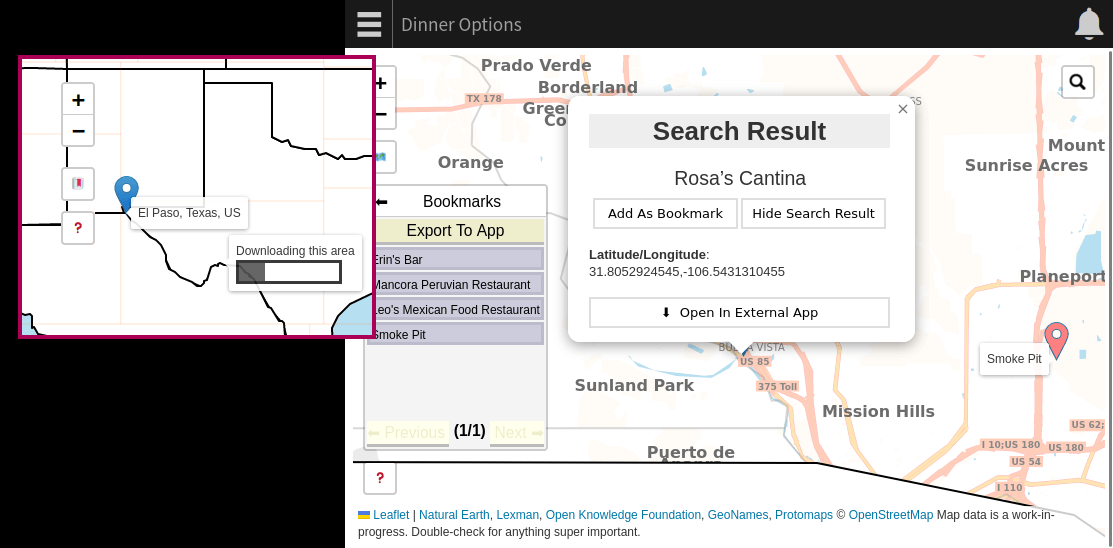
When you’re ready to take your map on the road, Desert Atlas is also a companion for Organic Maps (and OsmAnd). You can export your bookmarks from your sandstorm grain to your OSM phone app to navigate privately.
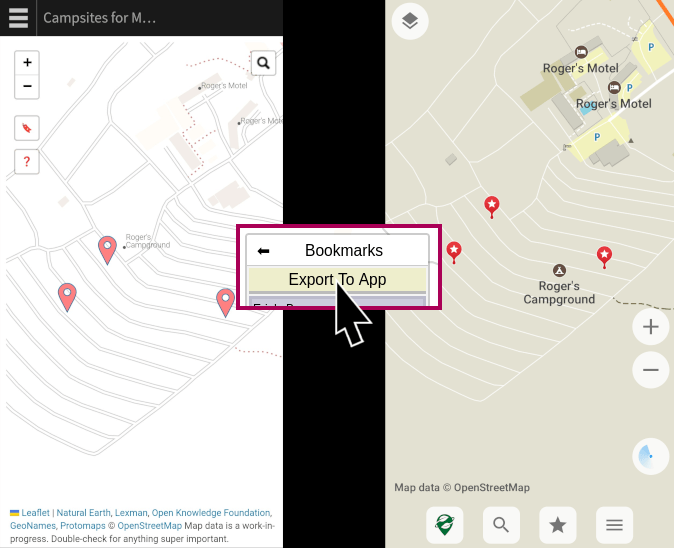
This has been the result of quite a bit of effort on my part, including learning more about the OpenStreetMap ecosystem than I ever thought I would. But since I had to learn a lot of things, I did not learn them very deeply. If you are inspired by this project and have deeper knowledge about some of its components, I have layed out some areas where you might be able to make a big impact pretty easily.
The gap between Organic Maps and Google Maps
Organic Maps allows you to search for destinations, navigate, and create bookmarks that can be imported or exported as KML files. It does all of these on your phone without hitting the network. The one concession to privacy is that the map data has to come from somewhere. The underlying map regions need to be downloaded initially and updated periodically. Organic Maps’ server knows what regions you are downloading, but they are each roughly the size of a small country, and it happens maybe once a week. This gives them much lower resolution than, say, requesting a specific intersection on demand from a centralized map website.
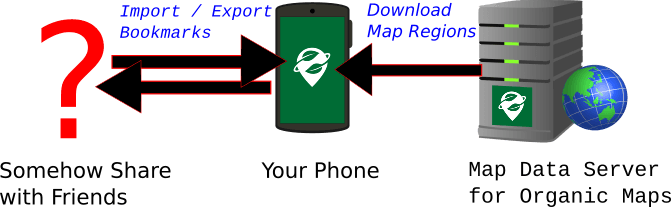
But what if you want to bookmark some spots for a night on the town and share them with some friends? Exporting and sending bookmark files is a bit inconvenient. There’s a web-based sharing feature for Organic Maps, but it reveals the location to Organic Maps’ server. If you want to plan the evening together, sharing KML files is especially inconvenient. You might find yourself using a different centralized service (Google Maps comes to mind but there are OSM-based options), even if you import the results to Organic Maps.
This is where a private web app comes in handy. Instead of collaborating and sharing on a centralized service, you can use Desert Atlas on a trusted Sandstorm server. When you’re done, you can each export the locations to Organic Maps for navigation and convenience. (And if you’re not sharing or collaborating, you can always stick to Organic Maps. It’s probably still more secure than a private web server sitting on the Internet.)
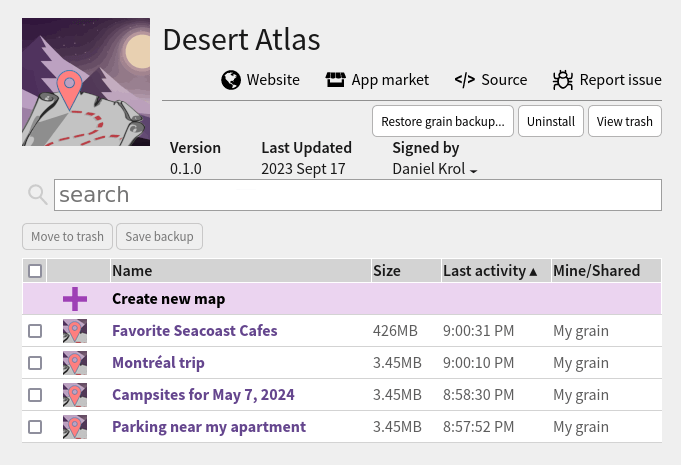
Some Similar Offerings
For comparison, I have looked at a couple other options for self-hosted OSM. I have not taken the time to try them out in depth, so apologies if I get something wrong.
Facilmap for YunoHost and Nextcloud Maps are made to be easy to set up and have similar use cases to Desert Atlas. They let you bookmark, plan trips, and share the results, all privately. But rather than downloading regions like Organic Maps, they get underlying map data from and send search terms to third-party services (such as openstreetmap.org), which leaks some usage information.
Headway is a project that solves this privacy problem. It installs the “full stack” of self-hosted OSM relatively easily. As you will see below, the OSM ecosystem has a lot going on, and Headway simplifies setup quite a bit. However, it uses Docker, which (in the humble opinion of Sandstorm fans) is still not as simple as Sandstorm. (I have seen a little discussion about porting it to YunoHost, but it has not happened as of this writing).
Desert Atlas takes a much more stripped down approach than Headway. Built for Sandstorm, with a lot fewer moving parts. I am not aware of any other offering that simultaneously lets you spin it up so easily (thanks to Sandstorm), point and click to download the regions you need, collaborate with friends, and have this level of privacy.
The Simplest Version of Everything
So how does this actually work? I kept it simple, which is not to say easy! While the implementation was not that hard, it took a lot of effort to find the right tools and learn how to integrate them. All the heavy lifting was already implemented by those tools. Big thanks to all those who created them.
OpenStreetMap is, among other things, a canonical database representing the world map. It is openly available and editable like Wikipedia. OSM applications such as Desert Atlas need to download this data in one way or another. Application creators usually provide their own copy of the data in a custom format that their apps download. They also use their own servers to spare the resources of openstreetmap.org. OpenStreetMap provides periodic snapshots of its database as one giant protobuf file known as planet.osm.pbf. Application creators can download it and extract what they need to make periodic snapshots of the data available to their users.
In general, the two parts of the OSM app experience are tiles and search.
Tile format
The traditional OpenStreetMap stack includes a tile server which imports the raw protobuf data into a Postgres database and generates a grid of square png files for every zoom level. Postgres is hard to get running on Sandstorm because it is made to be multi-user (though at one point I actually got a tile server to run and generate tiles in a test environment!) Alternately, as the provider of the map data for the app, I could have taken the path of pre-generating the png files for the app to download, but I suspect the resulting file size would be massive.
Then one day on Hacker News I saw something called Protomaps. It’s a project for vector-based tiles that render in the browser. It uses a file format called pmtiles. A single pmtiles file represents a region of the map at all zoom levels. You can use protomaps.js along with the Leaflet UI framework to view it. As you scroll or zoom, it makes range requests for the specific subset of the file that it needs to display it. No need for a database, or to generate anything within the Sandstorm app. Each downloadable region of the map has one pmtiles file.
And how do we create these pmtiles files? I did not want to regularly copy the entire world map from the Protomaps project. I set out to generate them myself from raw OSM data. The best way I could find was to first convert them to another vector format called mbtiles using a tool called tilemaker, and then from mbtiles to pmtiles using go-pmtiles from the Protomaps project.
Tile Schema
I generated my first pmtiles file and… nothing showed up. It turns out that on top of tile file formats, there is a concept of a schema. Protomaps.js turns out to have its own schema. Tilemaker uses a lua script to determine the schema of the mbtiles file it creates. The default lua script that comes with tilemaker is based on the OpenMapTiles schema. I initially set out to start with this lua script and edit it until the data it produced looked like the Protomaps schema. However, I was a little nervous because I was advised that OpenMapTiles has an uncertain intellectual property situation. I may or may not have misunderstood or overreacted, but at any rate I had an alternative. The folks at Geofabrik created their own schema called Shortbread that is licensed CC0 and comes with its own lua script for tilemaker. To steer clear of any concern over IP issues in creating my lua script to generate files in the Protomaps.js schema, I started from Shortbread.
Search Data
The standard option for an OpenStreetMap search service is called Nominatim. It uses Elasticsearch under the hood, which again is a bit heavy duty for Sandstorm. (edit: My mistake, it also uses Postgres, but the point stands). I asked myself, “what is the SQLite of search?” It turns out the answer is… SQLite! There is a plugin called FTS5 that performs reasonably well on Desert Atlas for searching names in the database. Desert Atlas does not yet support address search, so it remains to be seen how well suited FTS5 is for that.
To generate the search database, I decide what I want to extract from the raw protobuf for a given region using pyosmium. The result is saved to a CSV that gets bundled with the pmtiles file for the same region. When a user downloads a region inside Desert Atlas, the CSV is imported into the grain’s SQLite search database.
In addition to searching within downloaded regions, I decided that it would be useful to have cities and large towns built into the app so that the user can search for their city before they download any regions. This makes it easier for users to orient themselves and find which region they want to download. For this part, I used a pre-baked non-OSM database called GeoNames as a shortcut.
Splitting the world
Organic Maps is generally split by “administrative region”. It could be a country, state, or metro area, depending on how dense the information is. Ideally Desert Atlas would work the same way.
Geofabrik offers up-to-date raw OSM protobuf data split by regions in such a way. However, they have a download rate limit that I decided was prohibitive for this purpose, so I sought out to download OSM’s planet.osm.pbf and split it myself. Geofabrik also has a publicly available geojson file that defines the regions they offer for download, which I could in principle use to do the same splitting myself. However, the exact process that they use to slice the planet with this json file is not publicly available. In the long run I would like to figure this out.
For now, I found a “good enough” shortcut and I decided to take it. I split planet.osm.pbf using a tool called splitter from mkgmap. This tool splits raw OSM data into rectangles targeting a maximum raw data size per region. Unfortunately the render and search extractions done for Desert Atlas do not correspond 1:1 with the raw data, so the downloadable regions in Desert Atlas vary quite a bit in size, but I am shooting for about the same region size as Organic Maps.
UI
This part was straightforward. As mentioned above, I used Leaflet, which is the go-to web UI framework for OpenStreetMap. It’s extensible and worked well for me. I also used a plugin called Leaflet-Search that I was able to connect to the simple Python based backend and query the SQLite database.
So, in a nutshell…
Periodic map generation process (currently ~2.5 days)
- Download
planet.osm.pbf(world map raw protobuf) planet.osm.pbf-> rectangular region osm.pbf files (using splitter from mkgmap)- each region osm.pbf -> region .pmtiles with protomaps schema (using tilemaker and go-protomaps, with thanks to Geofabrik for the shortbread schema which I edited until it became the protomaps schema)
- each region osm.pbf -> region .csv with search data (using pyosmium)
- each region .pmtiles + .csv -> region .tar.gz -> upload to S3
App packaging
- bundle geojson files for low-res world and USA maps
- bundle cities and large towns from GeoNames
When a grain is created on the user’s Sandstorm server, the bundled GeoNames data is imported into the grain’s SQLite+FTS5 search database. The bundled geojson world and USA maps display thanks to Leaflet. The grain downloads whichever regions the user asks for from S3. For each region, the pmtiles file is ready to use as-is by protomaps.js and Leaflet, and the search CSV file is imported into the search database, with Leaflet-Search providing the UI.
Getting involved
If you are an OSM developer, you may or may not be facepalming right now. Likely some part of this could have been done in a better way. But you also know that OSM has a big, confusing ecosystem, with many ways of doing the same thing. This was my first exposure to a lot of it. This was a lot of work, and I wanted to forge a reasonable but efficient path to a minimum viable product.
It’s a modest submission of a usable proof of concept. I did not spend much time getting hung up on finding the very best way of doing everything on the first try, but at this point I am wide open to improvements, including replacing any part of this with something better.
See here for some areas that I think could be low hanging fruit, especially for people who can teach me about areas I am less familiar with (tiles, search, UI, front end) or just general improvements (rewriting the server in Go). Hit me up if you would like to help!
From .IO to .ORG
By Jacob Weisz - 03 Nov 2023
Sandstorm has been on a fairly slow and gradual transition from a dead startup to a community-operated open source project. Last week we posted our first update about our plans for the future of Sandstorm here on sandstorm.org, and now we’re going to explain what the domain change means going forward.
.IO doesn’t fit who we are today
The .io TLD has been a popular choice for startups for a number of years. However, it is a problematic TLD choice. One of our earliest key sponsors, draw.io, moved away from the domain a few years ago.
While the .org TLD has had its own share of problems, it’s large enough and established enough that the watchful eyes of the Internet have so far prevailed in protecting it. And the sandstorm.org domain better represents us as a nonprofit project mission-focused on bringing self-hosting to everyone.
A change of liability
Software that keeps itself updated, or “evergreen” is convenient and popular today, but it comes with a big risk: You trust the developer not just for the code they ship today, but for years into the future. You also are placing trust in the developer not to sell or give away that trust to someone else. Evergreen software like browser extensions have been known to be bought out in order to inject adware on unsuspecting users down the road.
Every Sandstorm server installed in the past ten years has entrusted Kenton Varda or Sandstorm Development Group with that level of access. While the members of our community have contributed to Sandstorm’s ecosystem for a number of years, we can’t ethically take over maintenance of Sandstorm servers without permission. While we are looking to extend and grow the ecosystem, server operators deserve the right to choose whether to trust us.
So as we develop a community-based path forward, we are going to ask server operators to opt-in to utilizing our releases and services, rather than taking them over.
Why are we doing this now?
The final, practical reason to make this fork now, is ultimately because of the project we are undertaking to upgrade Sandstorm’s database. This is a project we have found uncomfortable to automatically deploy, in case it leaves someone’s server in a non-working state.
By releasing that upgrade as a “fork”, it will allow administrators to take a backup of their server prior to both agreeing to entrust our team with future updates as well as migrating to the new version of the database. We plan to replace the references in the code to services currently hosted at sandstorm.io with sandstorm.org alternatives at the same time. And that minimizes the disruptive work of this process.
What about my Sandcats domain?
Sandcats is one of Sandstorm’s few “centralized services” which still runs today, so transferring it to our community would require a handoff of user data. We don’t want to do that without consent, so if we take over administration of the sandcats.io domain, we’ll provide significant advance notice and ensure only consenting users’ data is included.
The other issue with Sandcats is that its current infrastructure is fairly old, and before we look at taking over operation of the service, we need to update the platform and stand up a modern version of it.
This will be a very important process to get right, so we will talk about it often as we get closer to making any change that impacts users.
A thank you
Finally, I wanted to say thank you to our new backers who have contributed to our OpenCollective. We still have a ways to go in order to fund our database upgrade, but we are a lot closer today than we were a few weeks ago. Some people have reached out to ask how they can contribute to Tempest or app development, and it has been a delight to work with some great open source developers on app updates this month.
Sandstorm, Tempest, and the Future
By Jacob Weisz - 23 Oct 2023
Over the last couple of months, we have had a lot of people asking for an update on the project. We’ve had to take a bit of time for self-care before putting together our plans going forward, culminating in this update.
Note: Astute observers may notice this blog is on a new domain, sandstorm.org, along with subtle changes to this version of the website. We will discuss why and how this will impact our plans next week.
Remembering Ian Denhardt
As people closely following the project may already be aware, about three months ago one of our core project contributors, Ian Denhardt, sadly and unexpectedly passed away. It is impossible to overstate the significance of Ian’s contributions to this project, from maintaining and fixing bugs in Sandstorm itself, to packaging, re-packaging, and building a number of apps and tools, to starting a next-generation platform for Sandstorm (more on this below). Ian has ultimately been the primary contributor to our ecosystem as a whole for the past three years.
Ian was an incredibly gifted developer whose projects spanned from calendaring apps and backup tools to operating system kernels and programming languages. But far more than that, Ian was an incredibly humble and kind mentor and friend. Countless times he helped me with problems that came down to something close to “How do I navigate a Linux machine” without a hint of irritation. Steve Pomeroy shared a story about Ian recently that exemplified the sort of thought and care that he put into everything that he did.
We intend to honor Ian’s memory and vision by carrying forward his work and ensuring that we continue to make self-hosting viable for everyone.
Introducing Tempest
Since late last year, Ian had been working heavily on an experimental alternative software to run Sandstorm apps that we refer to as Tempest. Tempest is a modern take on the Sandstorm platform, supporting existing apps but dropping various long-disused compatibility shims and embracing modern technologies and expectations. It is written in Go, which is significantly more accessible to volunteer development than Meteor and C++. Another key feature is the use of WASM to allow the client side of the platform to also be written in Go and run Cap’n Proto directly in the browser.
Whereas Sandstorm was built with organization or SaaS provider scale as a focus, Tempest development was planned with individual or small community use at the forefront. One of the major goals Ian had intended to strive for with Tempest was the ability to communicate with decentralized communication networks like ActivityPub and Matrix, which has proven challenging for Sandstorm thus far.
As of this post, Tempest can run many Sandstorm apps and can import grains directly from a Sandstorm install. However, it is still far from being a production-usable application, and a lot of important API features for apps like external network access and web publishing are not implemented.
Multiple community members have stepped forward in the past two months to let us know that they would like to continue development of Tempest including Troy Farrell and Dan Krol. We plan to bring the current work on the project under the Sandstorm organization to coordinate that effort. If you are interested in contributing, please reach out on the project repository or the Sandstorm mailing list.
Current Challenges with Sandstorm
While Tempest has been exciting as a potential leap forward, everyone using Sandstorm today is still using “Sandstorm classic”. Sandstorm development has moved more slowly, but it has not stood still. Several security improvements have been added in the past couple of years, including improved sandboxing both on the server and client side and a number of small but impactful UI improvements. Last month, Sandstorm’s 308th release included Ian’s final contribution as well as additional localization work that Troy contributed.
Unfortunately, as we hope to continue to support Sandstorm long-term, we’ve had an increasingly challenging problem with the legacy MongoDB database underneath, as Meteor has dropped support for the version we use. Ensuring a seamless migration on end-user servers has proven to be a challenging problem. Dependency upgrades are not fun and this has become a fairly unpleasant project to undertake for unpaid open source contributors.
Moving Forward
Over the past few weeks, we have spoken to a number of potential outside parties about taking on this project and building a migration so that we can update the databases of existing Sandstorm servers and allow us to continue moving forward. We believe this is the best way to ensure that Sandstorm servers continue to be the safest way to self-host. The cost estimates we’ve discussed for the current Sandstorm aren’t unreasonable, but they are significant.
We are looking to raise the funding for this project through our OpenCollective. If you are using Sandstorm, especially at an organization level, and can help ensure that we are able to provide long-term support, please donate to the project. If you believe that you or your organization may be willing to fund this effort in large part or its entirety and would like additional details about the amount we would need to fund this, please contact me directly.
Sandstorm is approaching its tenth birthday, and there’s still nothing else like it. Capability-based security and a tireless focus on abstracting away complexity from the user continue to make it the only platform which holds hope of letting everyone, not just developers and IT professionals, self-host. Thank you for your continuing interest and support.